Hi there! My name is Peiwen Ren and I am a rising junior studying materials science and integrated science program at Northwestern. This summer, I am working with Jakob Elias and Thien Duong at the Energy and Global Security Institute. My project focuses on using natural language processing (NLP) to automatically extract material synthesis parameters in science literatures.
In recent years, many of the breakthroughs in deep learning and artificial intelligence are in the field of natural language processing. From the speech recognition apps like Siri and Google Assistant, to the question answering search engines, NLP has seen an unprecedented growth of popularity among the AI community. In addition, there have been increasingly more and more applications of NLP in fields like materials science, chemistry, biology and so on. A big challenge in materials science, as well as in chemistry, is that a huge amount of material synthesis knowledge is locked away in literatures. In many cases, after a material is made and the synthesis methods are recorded in a paper, the paper just goes un-noticed. As a result, many potential breakthroughs in materials discovery may have been delayed due to a lack of knowledge of prior work, or unnecessary duplicate studies are conducted only to realize they have been done before. The advantage of NLP, if properly developed, is that it can input a huge amount of texts and output summary information without the need of researchers going through the literatures themselves.
The end goal of this project is to pick out relevant synthesis parameters of the material mentioned in the given abstract or full document text. The advantage of this approach is that if a researcher wants to study a known compound or synthesize a new material, he or she can can just give the name of the compound of interests into the program, and the program will automatically query the existing science literature corpus to download all the papers mentioning the target compound. Then the extracted texts will be fed into a NLP model to pick out relevant synthesis parameter. One example would be given a sentence input, “Compound A was made with compound B by heating in the furnace at 300 degree celsius”, the NLP model would output a tagged sequence with the same length as the input sentence, but each entry corresponds to a pre-defined tag. The tagged output in this case would be “Compound A <TARGET>, was <O>, made <O>, with <O>, compound B <MATERIAL>, by <O>, heating <OPERATION>, in <O>, the furnace <SYNTHESIS-APPARATUS>, at <O>, 300 <NUMBER>, degree <O>, celsius <CONDITION-UNIT>, . <O>” This process of tagging a sequence of word is called named entity recognition (NER).
Here is a list explaining the tags mentioned above:
- <TARGET>: the target material(s) being synthesized
- <O>: null tag or omit tag
- <MATERIAL>: the material(s) used to make the target material(s)
- <OPERATION>: the action performed on material(s)
- <SYNTHESIS-APPARATUS>: equipment used for synthesis
- <NUMBER>: numerical values
- <CONDITION-UNIT>: the unit corresponding to the preceding numerical value
The following figure is a visualization of the tagging.

To realize this NER task, I trained a sequence to sequence (seq2seq) neural network using the pytorch-transformer package from HuggingFace. A seq2seq model basically takes in a sequence and outputs another sequence. The input and output sequence may not be of the same length, although in our sequence tagging task they are. A common use of seq2seq models is language translation, where for example a sequence of English words is put through a model and a sequence of French words is produced, or vice versa.

Since training a seq2seq model is a supervised learning problem (meaning the model needs labeled training set), a hand-annotated dataset containing 235 synthesis recipes was taken from the Github page of Professor Olivetti’s group at MIT. The dataset was downloaded in a nested JSON format, which was then flattened into a csv file using python’s Pandas package. Here is a preview of the training set.
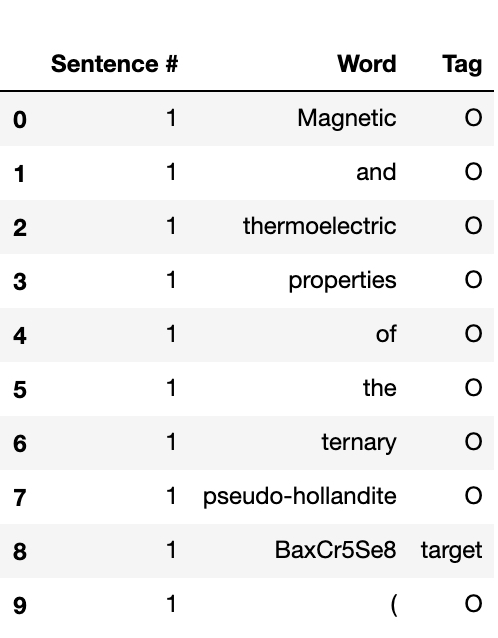
As seen in the figure above, each row represents a word, with “sentence #” specifying the index of the sentence it belongs to and “Tag” representing the pre-defined tag mentioned before. The data was then split into training data and validation/test data in a 90% : 10% ratio. The model was implemented using a pre-trained BERT model from Google Research on a single Nvidia Tesla T4 GPU. After running 5 epochs (1 epoch meaning a passthrough over the entire training set), the prediction accuracy of the model on validation/test set is 73.8%, and the F1 score is 19.8%. A similar model developed by the Olivetti group achieved 86% accuracy and 81% F1 score. [1]
There are two possible reasons for the low accuracy and F1 score:
- The NLP model utilized a NLP model specifically pre-trained on materials science literatures, whereas the BERT was pre-trained on Wikipedia entries and a list of book corpus with little focus on materials science topics.
- The BERT NLP model is predicting a lot of the null tags (“O”) to be meaningful named entities tags. For example, “is” may be predicted as “target” instead of “O”, leading to a large number of false positives in the predicted labels.
The following two figures show a visualization of a sentence prediction from the BERT NLP model.


In the figures above, we can see the the NLP models successfully assign correct tags to most words, except that it misclassifies “magnetic” as a APPARATUS-DESCRIPTOR rather than a SYNTHESIS-APPARATUS, and it fails to assign tags for the last three words “tumbling (60 rpm)”.
The next steps for this project would be to pre-train a model specifically focused on materials science literature and to tune down the false positive rate in the current NLP model, in order to increase the test accuracy and F1 score respectively.
The Jupyter Notebook and training data used for this project will be updated at this Github Repo. The code used for training the BERT model is modified from Tobias Sterbak‘s Named Entity Recognition with BERT post. This project is inspired by the works from Professor Olivetti’s group at MIT and Professor Ceder’s and Dr. Jain’s groups at UCB. [2]
References:
- Kim, E., et al. (2017). “Machine-learned and codified synthesis parameters of oxide materials.” Sci Data 4: 170127.
- L. Weston, V. T., J. Dagdelen, O. Kononova, K. A. Persson, G. Ceder and A. Jain (2019). “Named Entity Recognition and Normalization Applied to Large-Scale Information Extraction from the Materials Science Literature.” Preprint.